“莺花犹怕春光老,岂可教人枉度春?”
正文
之前有记笔记的习惯,但都是私人笔记,并且写的都很随意,所以就很少写在公共平台,正好最近工作稍微清闲,打算整理一下,一方面加深记忆,一方面与大家共享,反正文笔不好,不过应该能看懂,尽量用通俗的大白话来描述。
OK,言归正传。在理解KMP算法之前,来看一个这样的问题,就是一个字符串是否包含另一个字符串,比如A字符串为ABCDEF,B字符串为BC,则返回1,就是匹配的下标,如果B字符串为BD则返回-1,表示没有匹配成功。代码可以这样写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public static int match(String srString, String deString) {
int i = 0;
int j = 0;
while (i < srString.length() && j < deString.length()) {
if (srString.charAt(i) == deString.charAt(j)) {
i++;
j++;
} else {
//如果不匹配,就回退,从第一次匹配的下一个开始,
i = i - j + 1;
j = 0;
}
if (j == deString.length())
return i - j;
}
return -1;
}
测试一下
1
2
3
System.out.println(match("abcdef","bc"));
System.out.println(match("abcdef","bd"));
System.out.println(match("abcdef","de"));
看一下运行结果
1
2
3
1
-1
3
还可以这样写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static int match(String source, String pattern) {
boolean match;
for (int i = 0, len = source.length() - pattern.length(); i <= len; i++) {
match = true;
for (int j = 0; j < pattern.length(); j++) {
if (source.charAt(i + j) != pattern.charAt(j)) {
match = false;
break;
}
}
if (match) {
return i;
}
}
return -1;
}
再改一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public static int match(String source, String pattern) {
int len = source.length() - pattern.length();
for (int i = 0; i <= len; i++) {
for (int j = 0; j < pattern.length(); j++) {
if (source.charAt(i + j) == pattern.charAt(j)) {
if (j == pattern.length() - 1)
return i;
} else {
break;
}
}
}
return -1;
}
其实无论怎么改,原理还是一样的,就是每次先匹配source的第一个,如果失败再从第二个开始,以此类推,直到找到为止。可是这种方法效率并不高,比如在字符串ABCABXYABCABATDMN中查找ABCABA,当前面5个都匹配的时候,只有第6个X和A不匹配,这个时候再从第二个B开始比较显然效率不是很高,因为前面5个确定是一样的,这个可以加一利用。
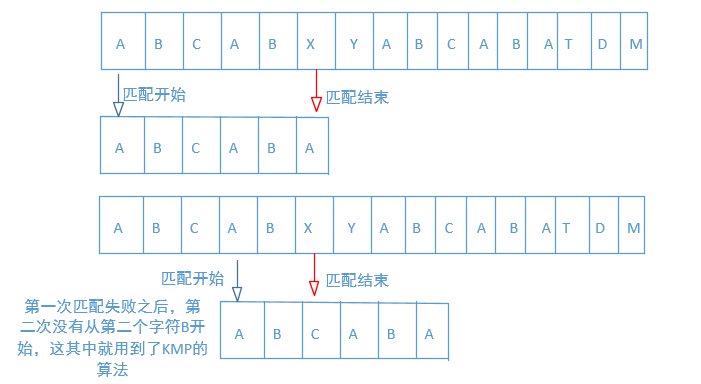

从上图可以看到,当第一次匹配失败的时候,第二次并不是从字符B开始,而是从下一个字符A开始,这样就提高了比较的效率,这个算法是怎么计算的,看一段代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public static int match(String source, String pattern) {
int i = 0;
int j = 0;
/**
* 数组next表示pattern指定的下标前具有相同的字符串数量,语言组织能力不好,可能不是太好理解,我举个例子吧
* ,比如ABCABA,数组next[0]是-1,这个是固定的,因为第一个A前面是没有字符的,next[1]是0,因为B的前面就一个A,没有
* 重复的,所以是0,同理next[2]也是,next[3]也是0,而next[4]是1,因为next[4]所指向的是第二个B,第二个B前面有一个A和
* 第一个A相同,所以是1,next[5]是2,因为next[5]所指向的是最后一个A,因为前面的A对比成功,并且B也对比成功,所以是2,
* 也就是AB两个字符串匹配成功,再举个例子,比如WABCABA,数组除了第一个为-1,其他的都是为0,因为只有第一个匹配成功之后
* 才能匹配后面的,虽然后面的AB和前面的AB匹配成功,但是后面AB的前面是C和前面AB的前面一个W不匹配,所以后面的匹配都是0.
* 要记住只有指定字符前面的字符和第一个字符匹配成功的时候才能往后匹配,否则后面的永远都是先和第一个匹配。
*/
int[] next = new int[pattern.length()];
getNext(pattern, next);
while (i < source.length() && j < pattern.length()) {
/**
* 这里j等于-1的时候也只有在下面next数组赋值的时候才会出现,并且只有在数组next[0]的时候才会等于-1,
其他时候是没有的,这一点要谨记,待会下面求next数组的时候就会用到。这里可以这样来理解,如果j不等于-1,
并且下标i和j所指向的字符相等,那么i和j分别往后移一位继续比较,这个很好理解,那么如果j==-1的时候,就表示
就表示前面没有匹配成功的,同时i往后移一位,j置为0(j==-1的时候,j++为0),再从0开始比较。
*/
if (j == -1 || source.charAt(i) == pattern.charAt(j)) {
i++;
j++;
} else {
/**
* i = i - j + 1;
j = 0;
返回到指定的位置,不是返回到匹配失败的下一个位置,这里都好理解,重点是求数组next。
这里只要j等于0,在next[j]赋值的之后,j就会等于-1;因为next[0]等于-1
*/
j = next[j]; // j回到指定位置
}
if (j == pattern.length())
return i - j;
}
return -1;
}
结合上面的图,再看上面的代码,理解会稍微容易一点。下面重点是求数组next,还是在代码中分析更好一些,看代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static void getNext(String p, int next[]) {
int len = p.length();
int i = 0;
int j = -1;
next[0] = -1;//这个默认的,
/**
* 匹配的时候是当前字符的前一个和前面的匹配,所以最后一个是不参与匹配的,可以看match方法的注释,
*/
while (i < len - 1) {
if (j == -1 || p.charAt(i) == p.charAt(j)) {
/**
* 如果j不等于-1,指定的字符相等,那么i和j要往后移一位,这点很好理解,如果j为-1的时候,i往后移移位,j置为0
* 重新开始匹配。next[i]是匹配成功的数量
*/
i++;
j++;
next[i] = j;
} else
/**
* 关键是这里不好理解,为什么匹配失败要让next[j]等于j,要记住这里的next[j]是指匹配成功的数量,有可能为0,也有可能是其他数.比如
* 字符串ABCABXYABCABATDM,对应的next数组为{-1 0 0 0 1 2 0 0 1 2 3 4 5 1 0 0 }
*
*/
j = next[j];
}
for (int k = 0; k < len; k++)
System.out.print(next[k] + "\t");
}
上面都有注释,如果不太明白,下面画一张图,更有助于理解

getNext方法中主要是j=next[j]不太好理解。上面的图分析的很清楚,可以结合着看一下,主要来看一下第18步当i=12和j=5的时候,因为A和X不等,所以第19步会让j=next[j],也就是next[5],也就是2,所以第19步的j为2,为什么不是从0开始,这就是这行代码的精髓所在,上面说过next[i]表示i之前所匹配的数量,如果next[j]等于0,说明之前没有匹配的,所以自然会从0开始,如果next[i]不等于0,说明前面有匹配成功的,既然有成功的,如果再从0开始,显然不科学。首先要理解这一点,在上面j等于5的时候匹配失败,说明在5之前是成功的,也就是说5(这里的5是下标,也就是第6个元素)之前的5个和12(i=12)之前的5个是匹配成功的,一般情况下下一步应该是从j等于0的时候开始匹配,但这里next[5]等于2,那么说明在下标为5之前还有2个是匹配成功的,也就是下标为5之前的2个和最开始的2个是匹配成功的,因为下标为5之前的5个和下标为12之前的5个是一样的,所以可以进一步推,也就是最开始的2个(AB)和下标为12之前的2个(AB)是一样的,所以这里就没必要从0开始比较,只需要比较最开始两个的后一个(也就是下标为2)和第12个比较就可以了。
其实这里的比较还不是最好的,下面看一个图
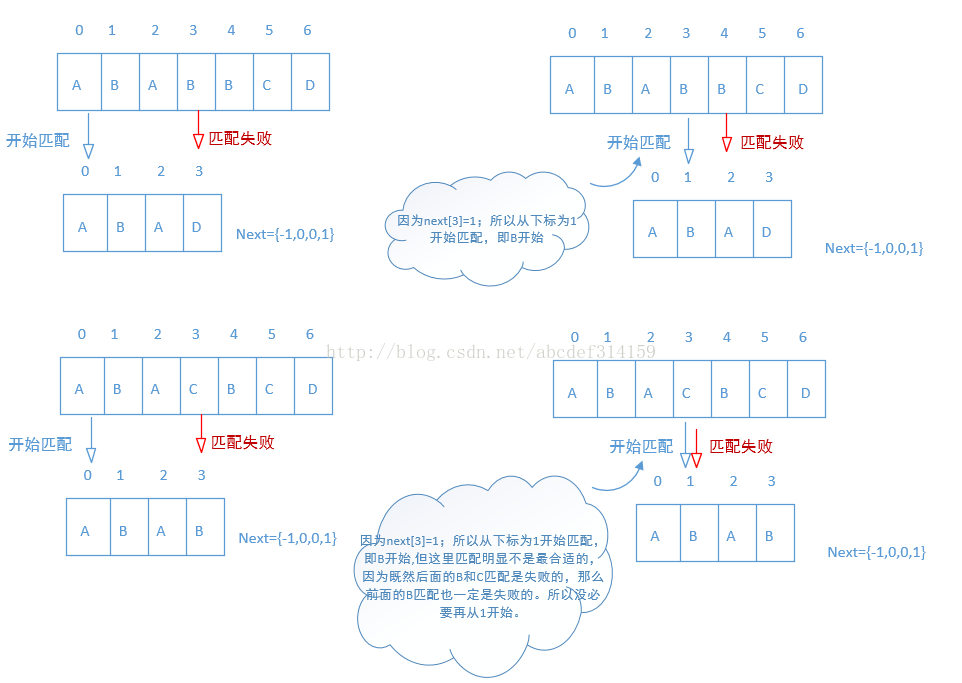
在上面的图中从下标为1开始明显的合理的,但下面的图明显是不合理的,因为下面有两个AB,当后一个B和指定的字符匹配失败之后,那么前面的B和指定字符匹配也一定是失败的,所以这里就没必要再从1开始,下面看代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
static void getNext(String p, int next[]) {
int len = p.length();
int i = 0;
int j = -1;
next[0] = -1;
while (i < len - 1) {
if (j == -1 || p.charAt(i) == p.charAt(j)) {
if (p.charAt(++i) == p.charAt(++j)) {
/**
* 这个是优化之后的,可以这样理解,当p.charAt(++i) == p.charAt(++j)的时候,如果p.charAt(++i)字符匹配失败,
* 那么在移到前面的时候,字符p.charAt(++j)也一定匹配失败,因为字符p.charAt(++i)和p.charAt(++j)是相等的,既然后面
* 一个失败,那么前面的也就没必要比较。继续往前移,移到下一个匹配的字符,其中next[j]表示在位置j匹配失败时j前面的n个字符
* 和最开始的n个字符是一样的,n就是next[j]的值,既然在j位置匹配失败,那么说明在j位置之前都是成功的,那么自然要移到next[j]
* 的位置开始匹配。
*/
next[i] = next[j];
} else {
//这个是之前写的那种,毋庸置疑
next[i] = j;
}
} else
j = next[j];
}
}
先打印几个值来看看
1
2
3
4
5
6
System.out.println(match("abcdef", "bc"));
System.out.println(match("abcdef", "de"));
System.out.println(match("abcdef", "ef"));
System.out.println(match("abcdef", "df"));
System.out.println(match("ABCABXYABCABATDM", "ABCABXYABCABATDM"));
System.out.println(match("0001……00001", "00001"));
看一下打印结果
1
2
3
4
5
6
1
3
4
-1
0
6
结果完全正确,OK,到现在为止,KMP算法已经分析完毕。